Benchmarking 7 LLMs from 4 providers on the same agentic task
GPT-5.1 scored 26%. Gemini 3 Flash scored 74.5%. Same prompt, same tools, same dataset. Most models weren't eliminated on accuracy.
In the previous article, I explained how I built the evaluation infrastructure for my AI agent: a hand-curated golden dataset, a 3-run minimum per config, and the discovery that 17% of items flip between identical runs. This article puts that infrastructure to use.
I'm building Mio, an app where you scan a product barcode and get the manufacturing country. The AI agent searches the web, reads pages, cross-references sources, and returns a country with a confidence level. I built the same agent pipeline for 5 providers: Gemini, Anthropic, OpenAI, xAI, and Mistral. Same prompt. Same tools. Same scoring.
Here's what happened when I ran them all against the same benchmark.
The four walls
This isn't a "which model is smartest" comparison. It's an elimination tournament. My agent runs inside a consumer app where people scan products in a store and wait for an answer. That sets hard constraints.
Latency: under 10 seconds ideally, 15 seconds max. At 20-30 seconds, users put their phone back in their pocket.
Cost: under ~$0.01 per scan. At $0.02, the unit economics don't work at scale.
Accuracy: above ~60% country match. Below that, the app feels broken. Users scan 3 products, get 2 wrong answers, and uninstall.
False confidence: as low as possible. The agent saying "verified: Made in France" when the product is made in China is worse than saying "I don't know."
If any single dimension is unacceptable, the model is out. Doesn't matter how good the other numbers are.
The eliminations
Mistral
Tested on the early eval dataset (10 items). Country match: 50%. Cost was the lowest of anything I tested ($0.0006/trace), latency was fine (10.5s). But 50% accuracy means the agent is guessing. Didn't proceed to the gold-curated benchmark.
GPT-5.1
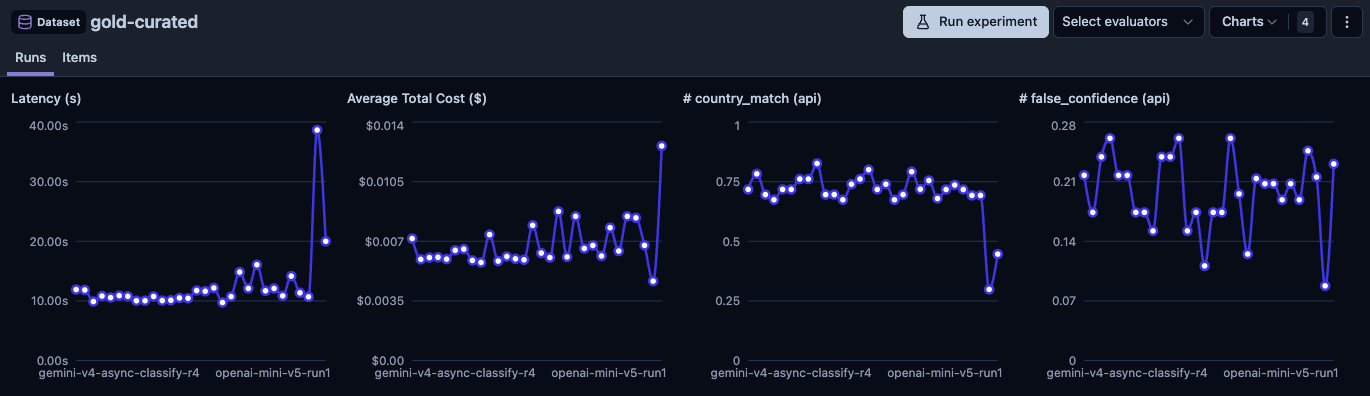
The most surprising result. GPT-5.1 is a strong model on public benchmarks. On my gold-curated dataset (34 items), it scored 26.5%. The model returned null/low confidence on almost everything. 20 out of 34 items were "other failures" where the agent never submitted an answer.
Honest caveat: I'm not 100% sure this is the model's fault. The OpenAI integration uses the Responses API, and tool results might not flow as effectively as Gemini's native function calling. But at 26.5%, I didn't invest more time debugging it. The other providers worked out of the box.
GPT-4.1
Tested on the early eval dataset (90 items, before gold-curated): 43% country match, $0.014/trace, 17.9s latency. Already below the accuracy threshold. When I tried to run it on the gold-curated dataset at concurrency 20, it immediately hit OpenAI's 30K tokens-per-minute rate limit. Unusable for benchmarking, let alone production.
xAI Grok 4 Fast
This one was interesting. Across multiple runs on 29-30 items, accuracy ranged from 40% to 72.4%. The best run (72.4%) was genuinely competitive. Cost was among the lowest ($0.001/trace). But latency killed it. Every run came in between 22 and 35 seconds. At 33.6 seconds average on the best-accuracy run, a user would be staring at a loading screen for half a minute.
If xAI gets the latency down, Grok is worth retesting. The accuracy signal was there.
Claude Haiku 4.5
The hardest elimination. Haiku got 67.6% accuracy on gold-curated (34 items), with 7 false confidence cases. Not far from Gemini 3 Flash (74.5%). On easy items, it hit 100%. Solid model.
But $0.019 per trace. That's 4-5x what Gemini costs. And latency was 17.4 seconds on the gold-curated run, with some eval-dev runs hitting 20-29 seconds. At $0.019/scan, 10,000 daily users doing 3 scans each means $570/day just in LLM costs. Gemini at $0.004/scan brings that to $120/day for better accuracy.
Sometimes a good model just doesn't fit the economics.
Gemini 2.5 Flash
The predecessor to the models I ended up using. 45.6% accuracy with the highest false confidence of any Gemini model (10.5 average across 2 runs). Also 2x more non-deterministic than Flash Lite: 37% of items flipped between identical runs, compared to 17% for Flash Lite. Bad accuracy, bad FC, unstable.
The survivors
Two Gemini models made it through all four walls.
Gemini 3.1 Flash Lite (runner-up)
54-60% accuracy (varies by run), FC around 4-7, latency 8.6s, cost ~$0.006/trace. This was my production model for a while. Low false confidence, decent cost, fast. But as I described in the prompt engineering article, it was stuck on a local optimum. Every prompt change I tried made things worse. The model was too simple to follow nuanced rules.
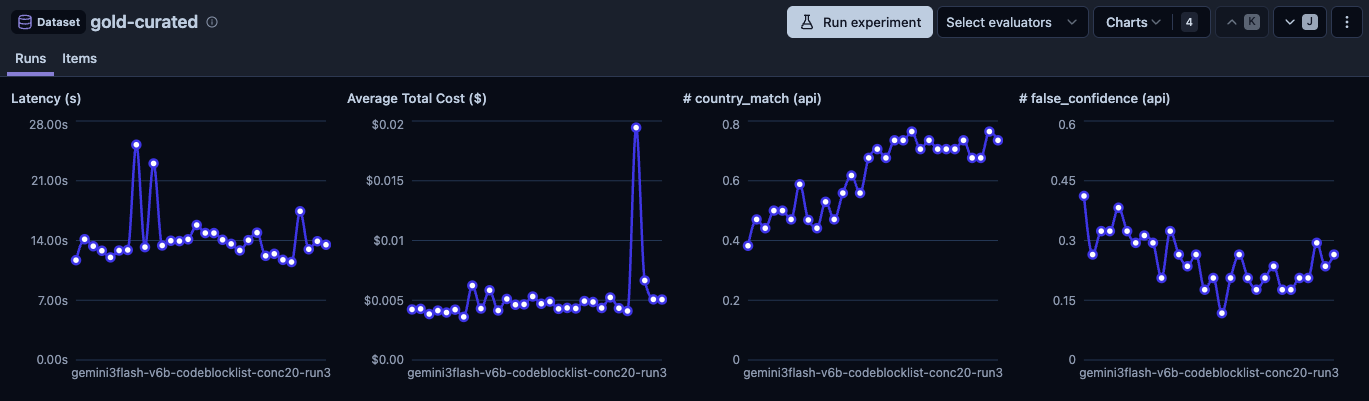
Gemini 3 Flash (the winner)
74.5% accuracy (average of 3 runs: 73.5%, 73.5%, 76.5%), FC 7.7, latency 13.5s, cost ~$0.004/trace. With parallel tool dispatch, the best single run hit 82.6%.
Gemini 3 Flash didn't win by being the best at any single dimension. Not the cheapest (Flash Lite was). Not the lowest FC (Flash Lite had ~5). Not the fastest (Flash Lite at 8.6s beat it). But it had the best balance: highest accuracy by a wide margin, within acceptable bounds on everything else. And unlike Flash Lite, it responded to prompt optimization.
What I learned
My takeaway: public benchmarks don't predict agentic performance. GPT-5.1 ranks high on MMLU, HumanEval, and other standard benchmarks. It scored 26.5% on my task. Gemini 3 Flash ranks lower on most public benchmarks. It scored 74.5%. Agentic tool-use tasks (search, read, reason, decide) test something completely different from "answer this question" benchmarks.
Most eliminations were about economics, not intelligence. Haiku at 67.6% would have been a perfectly good agent. Grok at 72.4% was competitive with Gemini. Both were eliminated on cost or latency, not accuracy. If you're building a backend service with no latency constraint and a generous budget, your winner might be completely different from mine.
Testing depth should match viability. I ran 100+ benchmarks on Gemini models and ~5 on every other provider. Deliberately uneven. It sounds unfair. But once a model hits a disqualifying wall, spending more benchmark budget on it is waste. I invested where it mattered.
Same prompt does not mean same results. All five providers got the exact same system prompt and tool definitions. The accuracy range was 26.5% to 74.5%. The prompt was designed for Gemini (it's where I iterated), which probably gives Gemini an advantage. A prompt optimized for Haiku or GPT might close some of the gap. But the cost/latency constraints would still eliminate them for my use case.
The unified architecture paid for itself. Building the agent for 5 providers with the same interface was serious engineering work. But it meant every comparison was apples-to-apples. Same prompt, same tools, same scoring, same dataset. No "well maybe the OpenAI version just has different tools." If a model underperformed, it was the model (or the API integration), not the setup.
The honest caveats
I want to be clear about what this benchmark does and doesn't show.
It shows how these models perform on my specific task (manufacturing country lookup via web search), with my specific prompt (optimized for Gemini), at my specific scale (consumer app, cost-sensitive). A different task, a different prompt, or different constraints could produce a completely different ranking.
The GPT-5.1 result in particular might not reflect the model's capability. If I'd spent more time on the OpenAI integration, the results might improve. I made a pragmatic choice: other providers worked immediately, so I invested time there instead.
And the testing depth is uneven. 3 runs on Haiku versus 20+ runs on Gemini 3 Flash means I have much more confidence in the Gemini numbers. The Haiku result (67.6%) could be an unlucky run. Or a lucky one. With 1 run, I don't know.
What I do know: Gemini 3 Flash at $0.004/trace and 13.5s gives me 74.5% accuracy. That's the combination I can build a product on. For now.
Because this benchmark is a snapshot, not a verdict. Prices drop. Models improve. Latency gets optimized. Haiku was eliminated on cost, but Anthropic's pricing changes regularly. Grok was eliminated on latency, but xAI is actively optimizing inference speed. GPT-5.1 might just need a different integration approach.
The elimination results are factual, but they're not permanent. The benchmark infrastructure stays. When the context changes, I'll rerun.
Next up: LLM-as-Judge: using Claude to review a Gemini agent. How I automated QA by having a smarter model review every agent trace, and the patterns it found that I never would have caught manually.
This is part of a series on building a production AI agent for Mio. Previous: Why your LLM agent needs a benchmark before it needs a prompt.
Frequently asked questions
-
It depends on your constraints. In my tests, Gemini 3 Flash scored 74.5% accuracy at $0.004/trace and 13.5s latency. Claude Haiku 4.5 got 67.6% but at $0.019/trace. GPT-5.1 scored 26.5%. Public benchmarks don't predict agentic performance. You need to benchmark on your specific task.
-
GPT-5.1 returned null or low confidence on 20 out of 34 items. This might be partly an integration issue (Responses API vs native function calling), not purely model capability. But at 26.5% on the only run, I chose to invest time in providers that worked out of the box.
-
In my tests: Gemini 3 Flash at $0.004/trace, Gemini Flash Lite at $0.006, Claude Haiku at $0.019, GPT-4.1 at $0.014, Mistral at $0.0006, and Grok 4 Fast at $0.001. For a consumer app with thousands of daily users, these differences are the difference between viable and not.
-
Not linearly. Gemini 2.5 Flash had 45.6% accuracy but the highest false confidence (10.5 avg). Flash Lite had lower accuracy (54-60%) but much lower false confidence (~5). Smarter models tend to answer more questions, which means more chances to be confidently wrong.