Why your LLM agent needs a benchmark before it needs a prompt
Before touching the prompt, I built a benchmark. It's what revealed that 17% of items give different results between identical runs, without changing a single line of code.
In the previous article, I showed how prompt optimization played out across three dimensions: prompt rules, tooling, and model capability. Some changes failed on one model and worked on another. Some only made sense once the tooling changed. Every claim in that article came with a specific number. "Accuracy dropped from 60% to 43%." "13 false confidence cases, worst run ever." "The same anti-FC rules went from catastrophic on Flash Lite to +10.8% on 3 Flash."
How did I know any of that?
Because before I wrote a single prompt engineering rule, I built the evaluation infrastructure to measure whether it worked. And the single most important thing that infrastructure revealed had nothing to do with prompts at all.
The most dangerous sentence in AI engineering
"It seems better on a few examples."
I hear this constantly from devs building with LLMs. They change the prompt, try it on 3-4 inputs, the outputs look better, they ship it. I did the same thing at the start. I'd tweak a rule, test it on the 2-3 products I had memorized, see an improvement, and commit.
This is how you ship broken changes without knowing.
The anti-false-confidence rules I wrote about in the last article? On a smaller model, they fixed the exact items I was testing against but dropped accuracy from 60% to 43% on everything else. On a smarter model weeks later, the same rules improved accuracy by +10.8%. Without a benchmark, I would have either shipped the broken version or permanently discarded rules that later turned out to be valuable.
You can't evaluate an AI agent by eyeballing outputs. You need a benchmark.
The golden dataset
A benchmark needs ground truth. For my agent (which finds manufacturing countries from product barcodes), that means: for each product, what's the actual country, and how confident should the system be?
My first attempt: I grabbed random EANs from my 69 million product database and ran about 30 benchmarks against them. It was useful for comparing models and getting rough numbers. But I kept running into a problem: when a run showed a regression, I wasn't sure if the agent got worse or if my "ground truth" was wrong. The expected countries had been found by the agent itself in earlier runs, verified by me with quick manual searches. Some were solid. Others, I wasn't confident enough to bet on.
I was building on sand. If your ground truth is shaky, your benchmark is noise. You can't tell an actual regression from a label error.
That's what pushed me to build the golden dataset properly. Each item hand-curated with a verified manufacturing country, a confidence level, and a difficulty rating.
The difficulty ratings matter:
- Easy: a product database already has the manufacturing country, or the first web search finds it
- Medium: needs 2-3 searches, maybe reading a retailer page, cross-referencing sources
- Hard: 3+ searches, white-label products, ambiguous evidence, or genuinely untraceable from public sources
The dataset grew over time: 21, then 30, then 34, then 46, then 53, then 57 items. I kept adding harder cases as the easy ones stabilized. This matters. A benchmark that only tests easy cases will tell you everything is fine when it isn't.
The curation pipeline works like this: a product gets scanned, the agent processes it, an LLM judge reviews the agent's trace, then I validate the review in an admin panel. If the ground truth is solid, I mark it as "gold" and it gets pushed to the benchmark dataset. It's slow. Each item takes serious verification work. But the whole point is that these labels are trustworthy. A benchmark with wrong labels is worse than no benchmark at all.
The metric that actually matters
I track 5 metrics on every benchmark run:
Plus latency and cost per trace.
Most people would optimize for country_match. Get the right answer more often. That's the obvious goal.
It's not the right goal. Or at least, it's not the only goal.
False confidence is the metric I optimize against. The agent says "verified: Made in France" and the product is actually made in China. That's the failure mode that destroys user trust*. One confidently wrong answer does more damage than ten "I don't know" results.
A concrete example from my data: the brand-level fallback I described in the last article got ~33% accuracy with 13 false confidence cases. A different config got 60% accuracy with 4 false confidence cases. The 60% config is obviously better for users, even though neither has great raw accuracy. Because 13 confident wrong answers means the user stops trusting the app.
But accuracy without cost/latency is meaningless. This is a consumer app. Someone scans a product in a grocery store and waits. During early testing, I benchmarked models that hit 70%+ accuracy but cost $0.02 per scan and took 20-30 seconds. A model at $0.004 per scan and 10 seconds that hits 65% is more shippable. The benchmark tracks cost and latency on every run precisely so I can make that trade-off with actual numbers instead of gut feeling.
The optimization target is a three-way balance: minimize false confidence, maximize accuracy, keep cost and latency within production-viable bounds. Not a single number. A region in a multi-dimensional space.
The day everything changed
About a week in, I had a baseline: 60% accuracy, 4 false confidence cases, on a 30-item dataset. I'd tried several prompt changes and they all seemed to make things slightly worse (53%, 57%, 50%). But the deltas were small. 1-2 items. Maybe just bad luck?
So I ran the exact same code a second time. Same model. Same prompt. Same config. Same dataset. Same everything.
Country match came out identical: 18/30 (60%) both runs.
But when I looked at the individual items, 5 out of 30 had flipped. Products that were correct in the first run were wrong in the second. Products that were wrong became correct. One item went from a correct answer to "unknown." Another went from "unknown" to the right answer with high confidence. False confidence went from 4 to 5.
17% of items gave different results on identical runs.
This was the most important finding of the entire project. It meant any delta of ±1-2 items was noise, not signal. Several "neutral" iterations I'd already tested were probably indistinguishable from the baseline. I needed at least ±4 items of difference on 30 items to have any confidence that a change was real.
I confirmed this later on a larger 46-item dataset. Two identical runs: 71.7% and 78.3%. That's a 7 percentage point gap on the same code. With 46 items, I needed a ≥10pp difference to call something significant.
This one finding changed how I evaluate everything.
The 3-run minimum
After the variance discovery, I established a rule: minimum 3 runs per configuration. No exceptions.
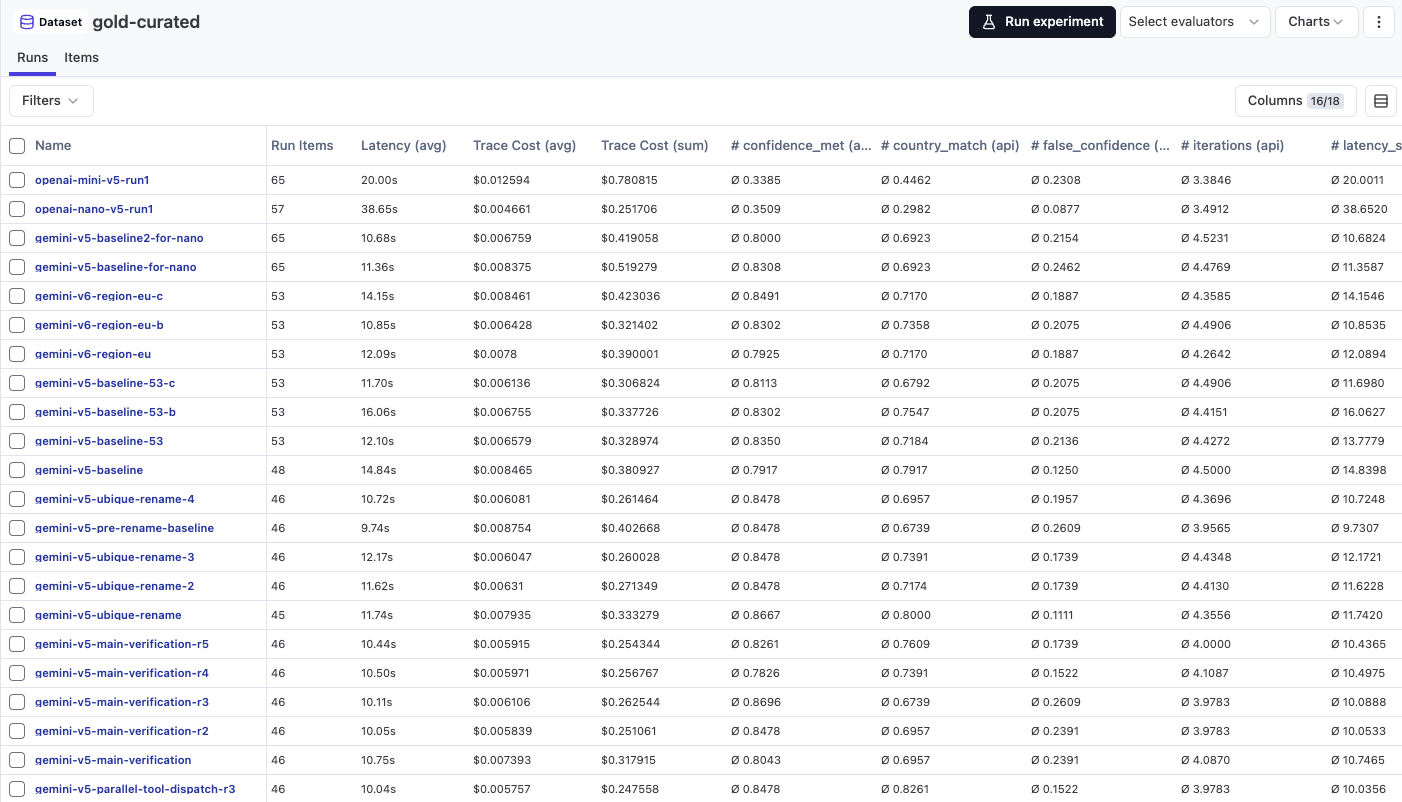
The big comparative session where I tested multiple models and prompt versions ran 3 models × 4 prompt versions, 3 runs each. The config I ended up shipping (Gemini 3 Flash with prompt v4) showed: 73.5%, 73.5%, 76.5% across its 3 runs. False confidence: 7, 9, 7.
That variance in FC (7 to 9 on identical code) is exactly why single runs are dangerous. If I'd only run it once and gotten the 9-FC run, I might have rejected a config that was actually the best option. If I'd only gotten the 7-FC run, I might have been overconfident about how good it was.
3 runs gives you the range. The average tells you where you probably are. The spread tells you how much to trust it.
Prompt versioning
Every benchmark trace in Langfuse records two things in its metadata: the PROMPT_VERSION constant and the git SHA. I bump the version on every prompt or pipeline change.
This means I can always trace back. "This run used prompt v4 at commit 36c5871." If a result looks weird, I can check out that exact commit and re-run it. Full reproducibility.
It sounds trivial. It's not. Without this, after 50+ runs, you lose track of what was tested when. "Was that the run with the anti-FC rules or without them?" is a question you never want to be asking.
Growing the dataset
The dataset started at 21 items, grew to 57, and sits at 69 as I write this. I kept adding harder cases as the easy ones stabilized.
My first baseline was 42% on 21 items. My production config hits around 78% on 46 items. But the 46-item dataset is harder than the 21-item one. I deliberately added products that are difficult to trace: white-label goods, brands that manufacture in multiple countries, products where "Made in France" on a retailer page actually refers to something else entirely.
A dataset that only gets easier over time is useless. If your benchmark accuracy goes up just because you're adding easy cases, you're measuring your dataset curation skills, not your agent.
The flip side: a dataset that gets harder over time means you can't compare run #1 to run #108 directly. You need to compare runs on the same dataset version. This is where the git SHA tracking pays for itself.
What I'd do differently
If I started over, two things:
Start with 30+ items from day one. My first benchmark had 21 items. That's too few. At 21 items, the variance is so high that almost nothing is statistically distinguishable from anything else. I wasted several days testing changes that were probably just noise. 30 items is the minimum where you start seeing actual signals. 50+ is where you get comfortable.
Track difficulty breakdown from the start. I added difficulty labels (easy/medium/hard) early, and it turned out to be one of the most useful dimensions. A change that improves easy items by 10% but destroys medium items is not a win, even if the overall number looks similar. The breakdown shows you where the change actually helps and where it hurts.
Why this matters beyond my project
If you're building an AI agent that does anything more complex than "turn this text into JSON," you need eval infrastructure before you need prompt engineering. The pattern is always the same:
- You change something
- It looks better on 3 examples
- You ship it
- It's actually worse on 80% of cases you didn't test
- You don't find out until users complain
The benchmark breaks this cycle. Instead of "it seems better," you get "accuracy went from 60% to 43%, with 5 new regressions on items that used to work." That's a sentence that changes your decision.
And the variance discovery applies to every LLM-based system, not just mine. If you're evaluating prompts with single runs, you're probably shipping noise. Run it 3 times. Look at the spread. You might find that your "10% improvement" was within the margin of error all along.
Next up: Benchmarking 7 LLMs from 4 providers on the same task. Same prompt, same tools, same dataset. GPT-5.1 scored 26%. Gemini 3 Flash scored 74.5%. The results were not what I expected.
This is part of a series on building a production AI agent for Mio. Previous: The prompt engineering that didn't work (and what did).
Frequently asked questions
-
At least 30 items to start seeing actual signals. With 21 items, the variance is so high that almost nothing is statistically distinguishable. I grew the dataset from 21 to 57 items over three weeks, deliberately adding harder cases as the easy ones stabilized. 50+ items is where you get comfortable.
-
False confidence is when the agent reports high confidence but is wrong. For example, "verified: Made in France" when the product is actually made in China. It's the most dangerous failure mode because one confidently wrong answer does more damage to user trust than ten "I don't know" results. I optimize against false confidence, not just raw accuracy.
-
In my tests, 17% of items gave different results on identical runs (same model, same prompt, same config, same dataset). On a 46-item dataset, two identical runs showed 71.7% and 78.3% accuracy. This means any delta of 1-2 items is noise, and you need at least 3 runs per configuration to distinguish actual improvements from random variance.
-
Both, but false confidence is more important. A config with 60% accuracy and 4 false confidence cases is obviously better for users than one with 33% accuracy and 13 false confidence cases. Accuracy without cost and latency context is also meaningless for production apps. Someone scanning a product in a store won't wait 25 seconds.