Pourquoi un agent IA a besoin d'un benchmark avant d'avoir besoin d'un prompt
Avant de toucher au prompt, j'ai construit un benchmark. C'est lui qui m'a appris que 17% des items changent de résultat d'un run à l'autre, sans modifier une ligne de code.
Dans l'article précédent, je racontais comment j'ai itéré sur le prompt de mon agent. Trois axes d'optimisation : les règles, l'outillage, le modèle. Des trucs qui cassaient tout sur un modèle marchaient sur un autre. Et chaque affirmation dans l'article était chiffrée : "60% à 43%", "13 faux positifs confiants, pire run du projet", "+10.8% sur 3 Flash avec les mêmes règles qui avaient tout cassé sur Flash Lite."
D'où venaient tous ces chiffres ?
D'un truc que j'ai construit avant de toucher au moindre prompt : l'infra d'évaluation. Deux semaines de boulot. Et le truc le plus important qu'elle m'a appris n'avait rien à voir avec les prompts.
La phrase la plus dangereuse en IA
"Ça a l'air mieux sur quelques exemples."
Tous les devs qui bossent avec des LLM font ça. Ils touchent au prompt, testent sur 3-4 inputs, ça a l'air mieux, ils ship. J'ai fait pareil au début. Je changeais une règle, je testais sur les 2-3 produits que je connaissais par coeur, ça s'améliorait, je committais.
C'est comme ça qu'on ship des trucs cassés sans s'en rendre compte.
Les règles anti-fausse-confiance dont je parlais dans le dernier article ? Sur un petit modèle, elles corrigeaient pile les items sur lesquels je testais, mais la précision chutait de 60% à 43% sur tout le reste. Des semaines plus tard, sur un modèle plus costaud, ces mêmes règles donnaient +10.8%. Sans benchmark, j'aurais soit shippé la version cassée, soit jeté des règles qui se sont avérées précieuses.
Évaluer un agent IA à l'oeil, ça marche pas. Il faut un benchmark.
Le golden dataset
Un benchmark, ça repose sur une vérité terrain. Mon agent cherche le pays de fabrication à partir d'un code-barres, donc il me faut pour chaque produit : le bon pays, et le niveau de confiance que l'agent devrait donner.
Au début, j'ai fait simple : des EAN au hasard dans ma base de 69 millions de produits, une trentaine de benchmarks. Utile pour dégrossir. Mais un truc me bloquait : quand un run montrait une régression, impossible de savoir si l'agent avait régressé ou si c'était mon label qui était faux. Les pays attendus, c'était l'agent lui-même qui les avait trouvés sur des runs précédents. Moi j'avais vérifié vite fait avec quelques recherches. Certains labels étaient solides. D'autres, j'aurais pas mis ma main à couper.
Je construisais sur du sable. Vérité terrain bancale = benchmark inutile.
Du coup j'ai construit le golden dataset proprement. Chaque item vérifié à la main : pays de fabrication, niveau de confiance, note de difficulté.
Les niveaux de difficulté, c'est pas du décor :
- Easy : une base de données produit a déjà le pays de fabrication, ou la première recherche web le trouve
- Medium : 2-3 recherches nécessaires, peut-être lire une page retailer, croiser des sources
- Hard : 3+ recherches, produits marque distributeur, preuves ambiguës, ou introuvable dans les sources publiques
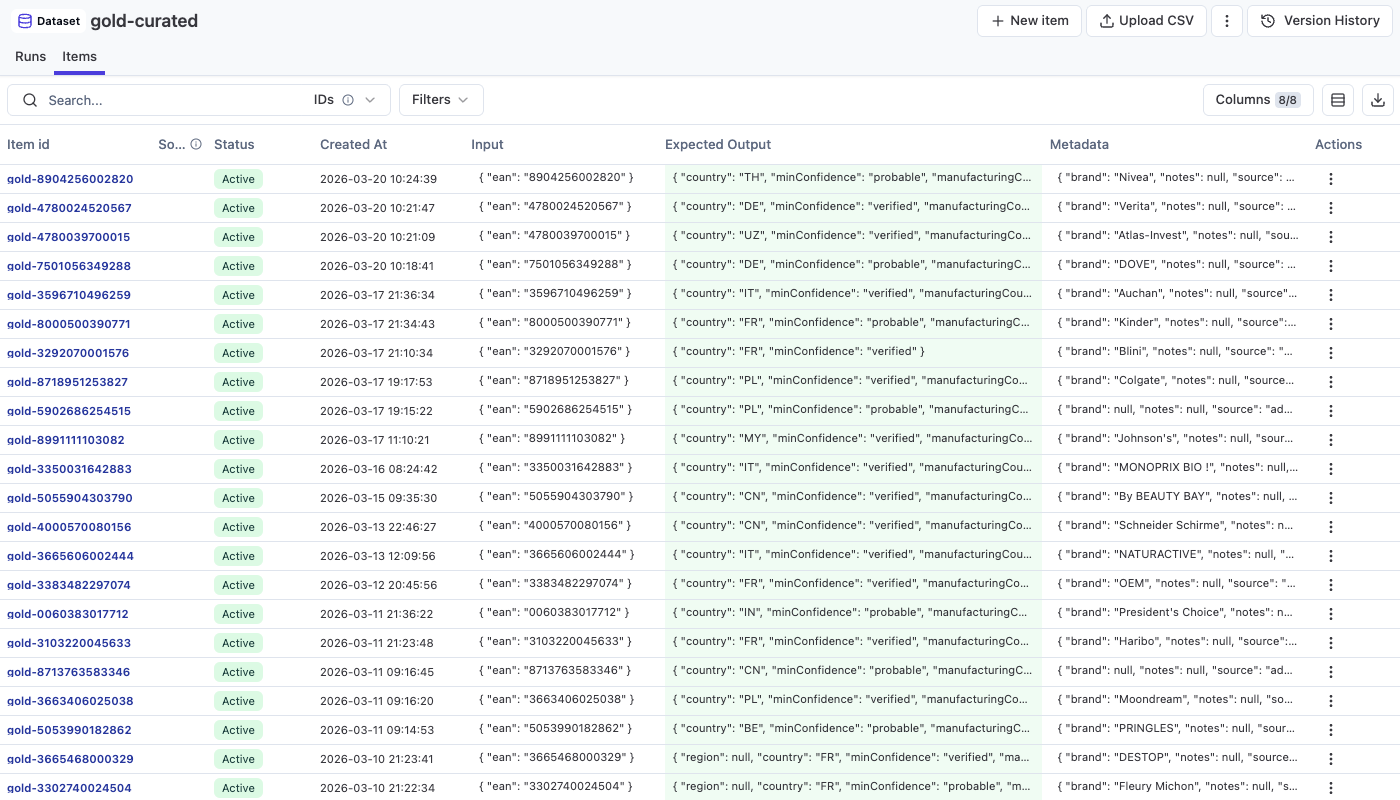
Le dataset a grandi au fil du temps : 21, 30, 34, 46, 53, 57 items. J'ajoutais des cas durs au fur et à mesure que les faciles se stabilisaient. Un benchmark qui ne teste que du facile, ça te berce d'illusions.
Le pipeline de curation, concrètement : un produit est scanné, l'agent le traite, un juge LLM analyse la trace, je valide dans l'admin. Si le label tient la route, je le marque "gold" et il rejoint le dataset. C'est lent, chaque item demande du boulot. Mais c'est le deal : des labels fiables. Un benchmark avec des labels faux, c'est pire que pas de benchmark.
La métrique qui compte
Je mesure 5 métriques à chaque run de benchmark :
Et en plus, la latence et le coût par trace.
Le réflexe, c'est d'optimiser country_match. Trouver le bon pays plus souvent. Logique.
Sauf que c'est pas le bon objectif. Ou pas le seul.
Ce que j'optimise en priorité, c'est la fausse confiance. L'agent dit "vérifié : fabriqué en France" et le produit vient de Chine. C'est ça qui tue. Une seule réponse fausse mais confiante fait plus de dégâts que dix "je ne sais pas".
Exemple concret : le fallback par marque dont je parlais dans le dernier article tapait ~33% avec 13 cas de fausse confiance. Une autre config tapait 60% avec 4. La config à 60% est évidemment meilleure, même si 60% c'est pas fou. 13 réponses fausses mais sûres d'elles, et l'utilisateur lâche l'app.
La précision sans le coût et la latence, ça sert à rien non plus. C'est une app grand public. Le mec scanne un produit au rayon et attend. Au début, j'avais des modèles à 70%+ mais à 0.02$ par scan et 20-30 secondes. Un modèle à 0.004$ et 10 secondes qui tape 65%, c'est plus shippable. Le benchmark mesure le coût et la latence à chaque run pour que je fasse ce compromis avec des chiffres, pas au doigt mouillé.
En gros la cible c'est pas un chiffre. C'est un équilibre : fausse confiance minimale, précision maximale, coût et latence qui tiennent en prod.
Le jour où tout a changé
Au bout d'une semaine, j'avais ma baseline : 60%, 4 fausses confiances, 30 items. J'avais testé plusieurs changements de prompt. Tous rendaient les choses un peu pires (53%, 57%, 50%). Mais les écarts étaient minuscules. 1-2 items. Peut-être juste pas de bol ?
J'ai relancé exactement le même code. Même modèle. Même prompt. Même config. Même dataset. Zéro changement.
Country match identique : 18/30 (60%) les deux fois.
Sauf que item par item, 5 sur 30 avaient bougé. Des produits corrects au premier run sortaient faux au second. Des faux devenaient corrects. Un item est passé d'une bonne réponse à "inconnu." Un autre a fait le chemin inverse, haute confiance. La fausse confiance est passée de 4 à 5.
17% des items changeaient de résultat d'un run à l'autre, sans rien modifier.
C'est la découverte la plus importante de tout le projet. Ça voulait dire qu'un écart de ±1-2 items, c'était du bruit. Pas du signal. Plusieurs itérations "neutres" que j'avais déjà testées étaient probablement identiques à la baseline. Il me fallait au moins ±4 items d'écart sur 30 pour pouvoir dire qu'un changement avait un effet.
Confirmé plus tard sur un dataset de 46 items. Deux runs identiques : 71.7% et 78.3%. Sept points d'écart sur le même code. Avec 46 items, il fallait ≥10pp d'écart pour considérer un résultat significatif.
Ça a changé ma façon de tout évaluer.
Minimum 3 runs
Après ça, nouvelle règle : minimum 3 runs par config. Non négociable.
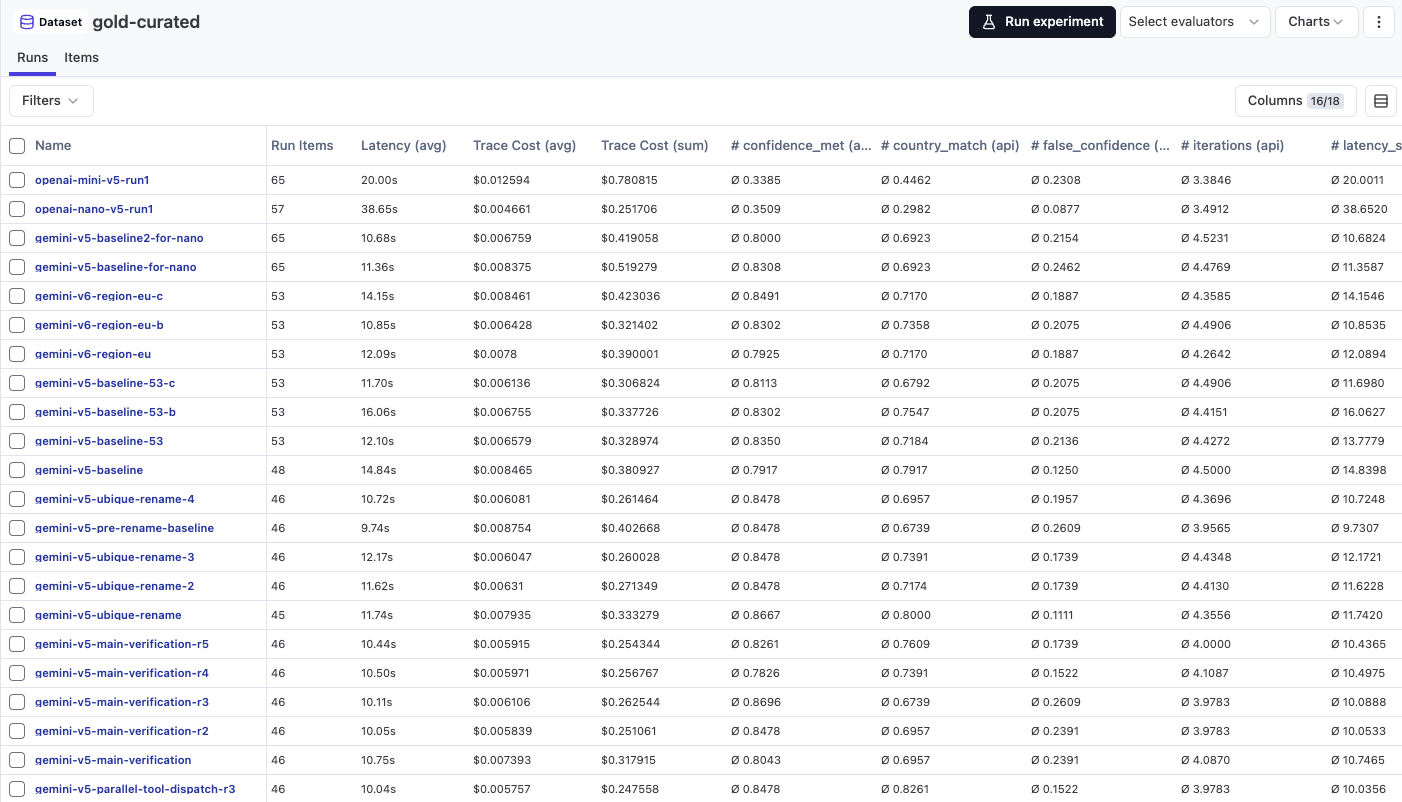
La grosse session comparative (3 modèles × 4 prompts, 3 runs chacun), la config que j'ai finie par shipper (Gemini 3 Flash, prompt v4) donnait : 73.5%, 73.5%, 76.5%. Fausse confiance : 7, 9, 7.
FC qui passe de 7 à 9 sur du code identique. C'est exactement pour ça que les runs uniques sont dangereux. Si j'étais tombé sur le run à 9 FC, j'aurais peut-être jeté ma meilleure config. Si j'avais eu le 7 seulement, j'aurais surestimé.
3 runs, ça donne la fourchette. La moyenne dit à peu près où t'en es. L'écart dit si tu peux t'y fier.
Versioning du prompt
Chaque trace de benchmark dans Langfuse enregistre la constante PROMPT_VERSION et le SHA git en metadata. Je bumpe la version à chaque changement de prompt ou de pipeline.
Du coup je peux toujours remonter le fil. "Ce run, c'était le prompt v4 au commit 36c5871." Résultat bizarre ? Je checkout ce commit et je relance. Reproductibilité totale.
Ça a l'air trivial. Ça l'est pas. Après 50+ runs, sans ça tu sais plus ce qui a été testé quand. "C'était le run avec les règles anti-FC ou sans ?" Pas le genre de question que t'as envie de te poser.
Faire grandir le dataset
21 items au départ, 57 ensuite, 69 à l'heure où j'écris cet article. Au fur et à mesure que les cas faciles se stabilisaient, j'en ajoutais des durs. C'est important. C'est aussi chiant, parce que du coup les chiffres de précision entre différentes tailles de dataset sont pas comparables.
Première baseline : 42% sur 21 items. Config de prod : ~78% sur 46 items. Sauf que le dataset de 46 est beaucoup plus dur que celui de 21. J'ai ajouté exprès des produits galère : marques distributeur, marques qui fabriquent dans 5 pays, produits où "Fabriqué en France" sur une page retailer parle d'un autre produit.
Un dataset qui devient plus facile avec le temps, ça sert à rien. Si ta précision monte juste parce que tu ajoutes des cas faciles, tu mesures tes skills de curation, pas ton agent.
Le revers : un dataset qui se durcit, ça veut dire que le run #1 et le run #108 sont pas comparables. Faut comparer sur la même version du dataset. C'est là que le SHA git se rentabilise.
Ce que je ferais différemment
Si c'était à refaire :
30+ items dès le jour 1. Mon premier benchmark en avait 21. Trop peu. À 21, la variance est telle que quasiment rien n'est distinguable. J'ai perdu des jours à tester des changements qui étaient du bruit. 30, c'est le minimum pour voir des signaux. 50+, c'est confortable.
Le breakdown par difficulté dès le départ. J'ai mis les labels easy/medium/hard assez tôt, et c'est devenu un de mes meilleurs outils. Un changement qui améliore les easy de 10% mais qui détruit les medium, c'est pas un progrès, même si le chiffre global bouge pas. Le breakdown montre où ça aide et où ça casse.
Pourquoi ça dépasse mon projet
Si tu construis un agent IA qui fait plus que "transforme ce texte en JSON," monte ton infra d'éval avant de toucher au prompt. Sinon t'es condamné à ce cycle :
- Tu changes un truc
- Ça a l'air mieux sur 3 exemples
- Tu ship
- C'est pire sur 80% des cas que t'as pas testés
- Tu le découvres quand les utilisateurs râlent
Le benchmark casse ça. Au lieu de "ça a l'air mieux," t'as "60% à 43%, 5 régressions sur des items qui marchaient." Ça, ça change une décision.
Et le truc de la variance, c'est pas spécifique à mon projet. Ça touche tous les systèmes LLM. Si tu évalues tes prompts sur un seul run, tu ship du bruit. Lance 3 fois. Regarde l'écart. Ton "amélioration de 10%" est peut-être dans la marge d'erreur depuis le début.
Prochain article : 7 LLM de 4 fournisseurs sur la même tâche. Même prompt, mêmes outils, même dataset. GPT-5.1 : 26%. Gemini 3 Flash : 74.5%. J'attendais pas du tout ces résultats.
Cet article fait partie d'une série sur la construction d'un agent IA en production pour Mio. Précédent : Le prompt engineering qui n'a pas marché (et ce qui a marché).
Questions fréquentes
-
Au moins 30 pour commencer à voir des signaux fiables. Avec 21 items, la variance est tellement élevée que presque rien n'est statistiquement distinguable. Le dataset est passé de 21 à 57 items en trois semaines, en ajoutant volontairement des cas difficiles au fur et à mesure que les cas simples se stabilisaient. À 50+ items, ça devient confortable.
-
La fausse confiance, c'est quand l'agent rapporte une confiance élevée alors qu'il se trompe. Par exemple, "vérifié : fabriqué en France" alors que le produit vient de Chine. C'est le mode de défaillance le plus dangereux parce qu'une réponse fausse mais confiante détruit plus la confiance utilisateur que dix réponses "je ne sais pas".
-
Dans mes tests, 17% des items donnaient des résultats différents sur des runs identiques (même modèle, même prompt, même config, même dataset). Sur un dataset de 46 items, deux runs identiques ont donné 71.7% et 78.3% de précision. Ça veut dire qu'un delta de 1-2 items, c'est du bruit, et qu'il faut minimum 3 runs par configuration pour distinguer une amélioration d'une variation aléatoire.
-
Les deux, mais la fausse confiance est plus importante. Une config à 60% de précision avec 4 cas de fausse confiance est clairement meilleure pour les utilisateurs qu'une config à 33% avec 13 cas de fausse confiance. Et la précision sans contexte de coût et latence n'a aucun sens pour une app en production. Personne ne va attendre 25 secondes en scannant un produit en magasin.