7 LLM de 4 fournisseurs sur la même tâche agentique
GPT-5.1 : 26%. Gemini 3 Flash : 74.5%. Même prompt, mêmes outils, même dataset. Et la plupart des modèles n'ont pas été recalés sur la précision.
Dans l'article précédent, j'expliquais comment j'ai construit l'infra d'évaluation de mon agent : un golden dataset curé à la main, minimum 3 runs par config, et la découverte que 17% des items changent de résultat d'un run à l'autre. Cet article met cette infra au boulot.
Je développe Mio, une app qui scanne un code-barres et trouve le pays de fabrication. L'agent IA cherche sur le web, lit des pages, croise les sources, et renvoie un pays avec un niveau de confiance. J'ai construit le même pipeline pour 5 fournisseurs : Gemini, Anthropic, OpenAI, xAI et Mistral. Même prompt. Mêmes outils. Même scoring.
Et je les ai tous lancés sur le même benchmark.
Les quatre murs
C'est pas un comparatif "quel modèle est le plus intelligent". C'est un tournoi d'élimination. Mon agent tourne dans une app grand public où les gens scannent des produits au rayon et attendent une réponse. Ça pose des contraintes dures.
Latence : en dessous de 10 secondes idéalement, 15 max. À 20-30 secondes, le téléphone retourne dans la poche.
Coût : en dessous de ~0.01$ par scan. À 0.02$, l'économie tient pas à l'échelle.
Précision : au-dessus de ~60% de country match. En dessous, l'app donne l'impression de pas marcher. L'utilisateur scanne 3 produits, en a 2 faux, et désinstalle.
Fausse confiance : le plus bas possible. L'agent qui dit "vérifié : fabriqué en France" alors que le produit vient de Chine, c'est pire que "je ne sais pas".
Un seul critère qui passe pas, et le modèle dégage. Les autres chiffres ont beau être bons, ça change rien.
Les éliminations
Mistral
Testé sur le premier jeu d'éval (10 items). Country match : 50%. Le coût le plus bas de tous (0.0006$/trace), latence correcte (10.5s). Mais 50% de précision, c'est du pile ou face. Pas passé au benchmark gold-curated.
GPT-5.1
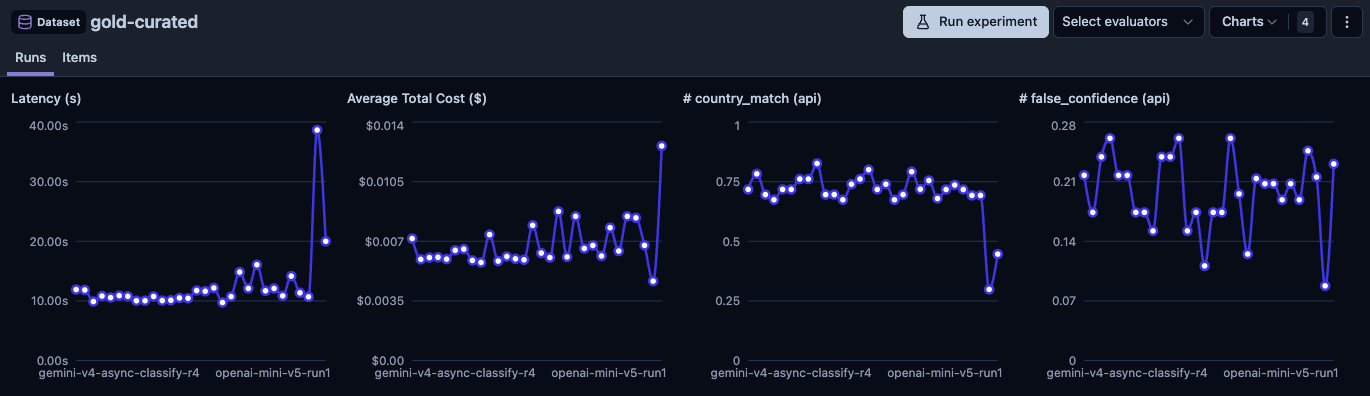
Le résultat le plus surprenant. GPT-5.1, c'est un modèle costaud sur les benchmarks publics. Sur mon dataset gold-curated (34 items) : 26.5%. Le modèle renvoyait null ou confiance basse sur quasi tout. 20 items sur 34 étaient des "other failures" où l'agent n'a même pas soumis de réponse.
En toute honnêteté : je suis pas sûr à 100% que ce soit la faute du modèle. L'intégration OpenAI passe par la Responses API, et les résultats d'outils sont peut-être pas passés aussi proprement qu'avec le function calling natif de Gemini. Mais à 26.5%, j'ai pas investi plus de temps à débugger. Les autres providers marchaient directement.
GPT-4.1
Testé sur l'ancien jeu d'éval (90 items, avant le gold-curated) : 43% de country match, 0.014$/trace, 17.9s de latence. Déjà en dessous du seuil de précision. Et quand j'ai essayé de le lancer sur le dataset gold-curated à concurrency 20, il a tapé direct dans le rate limit OpenAI de 30K tokens/minute. Inutilisable en benchmark, encore moins en prod.
xAI Grok 4 Fast
Celui-là était intéressant. Sur plusieurs runs (29-30 items), la précision allait de 40% à 72.4%. Le meilleur run (72.4%) était compétitif avec Gemini. Le coût parmi les plus bas (0.001$/trace). Mais la latence a tout cassé. Chaque run tombait entre 22 et 35 secondes. À 33.6 secondes de moyenne sur le meilleur run, l'utilisateur fixe un écran de chargement pendant une demi-minute.
Si xAI baisse la latence, Grok vaut le coup d'être retesté. Le signal de précision était là.
Claude Haiku 4.5
L'élimination la plus difficile. Haiku tapait 67.6% sur le gold-curated (34 items), avec 7 cas de fausse confiance. Pas loin de Gemini 3 Flash (74.5%). Sur les items easy, 100%. Un bon modèle.
Sauf que 0.019$ par trace. C'est 4 à 5 fois le coût de Gemini. Et la latence montait à 17.4 secondes sur le run gold-curated, avec des runs d'éval qui tapaient 20-29 secondes. À 0.019$/scan, 10 000 utilisateurs quotidiens à 3 scans chacun, ça fait 570$/jour rien qu'en coûts LLM. Gemini à 0.004$/scan ramène ça à 120$/jour. Pour une meilleure précision.
Un bon modèle qui coûte trop cher, ça reste un modèle qu'on peut pas utiliser.
Gemini 2.5 Flash
Le prédécesseur des modèles que j'utilise aujourd'hui. 45.6% de précision avec la pire fausse confiance de tous les Gemini (10.5 en moyenne sur 2 runs). Et 2 fois plus instable que Flash Lite : 37% des items changeaient de résultat entre deux runs identiques, contre 17% pour Flash Lite. Mauvaise précision, mauvaise FC, résultats instables.
Les survivants
Deux modèles Gemini ont passé les quatre murs.
Gemini 3.1 Flash Lite (finaliste)
54-60% de précision (ça varie selon les runs), FC autour de 4-7, latence 8.6s, coût ~0.006$/trace. C'était mon modèle de prod pendant un moment. Fausse confiance basse, coût correct, rapide. Mais comme je le racontais dans l'article sur le prompt engineering, il était coincé sur un optimum local. Chaque changement de prompt dégradait les résultats. Le modèle était trop simple pour suivre des règles nuancées. Plafonné.
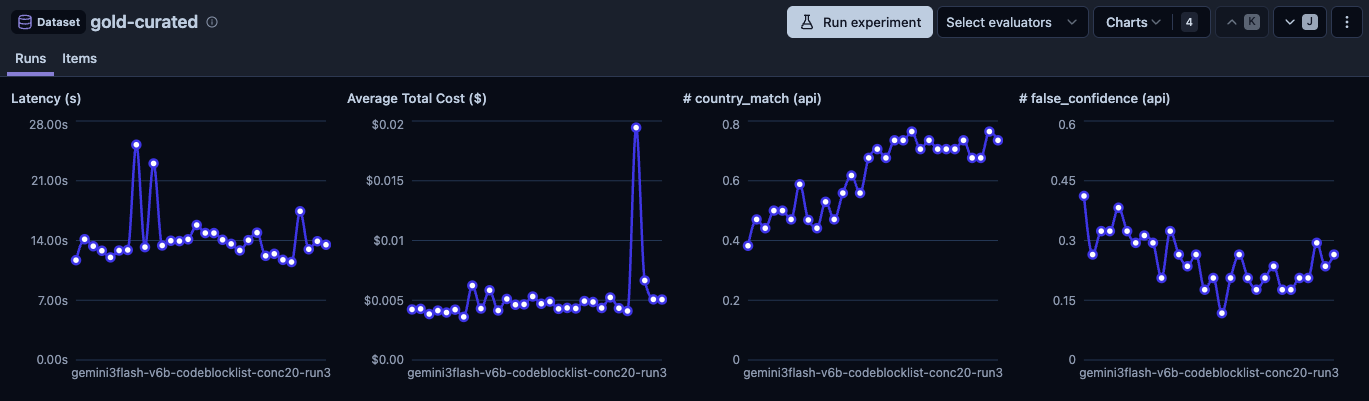
Gemini 3 Flash (le gagnant)
74.5% de précision (moyenne de 3 runs : 73.5%, 73.5%, 76.5%), FC 7.7, latence 13.5s, coût ~0.004$/trace. Avec l'exécution parallèle des outils, le meilleur run a tapé 82.6%.
Gemini 3 Flash n'a pas gagné en étant le meilleur sur un seul critère. Pas le moins cher (Flash Lite l'était). Pas la FC la plus basse (Flash Lite était à ~5). Pas le plus rapide (Flash Lite à 8.6s le battait). Mais c'est lui qui avait le meilleur équilibre : la précision la plus haute de loin, et des chiffres acceptables partout ailleurs. Et contrairement à Flash Lite, **il répondait à l'optimisation du prompt**.
Ce que j'en retiens
J'ai l'impression que les benchmarks publics ne prédisent pas la performance agentique. GPT-5.1 est bien classé sur MMLU, HumanEval, et les benchmarks classiques. Sur ma tâche : 26.5%. Gemini 3 Flash est plus bas sur la plupart des benchmarks publics. Sur ma tâche : 74.5%. Les tâches agentiques avec du tool use (chercher, lire, raisonner, décider) testent quelque chose de complètement différent.
La plupart des modèles n'ont pas été recalés sur la précision, mais sur le prix ou la vitesse. Haiku à 67.6% aurait fait un agent correct. Grok à 72.4% était compétitif avec Gemini. Les deux ont été éliminés sur le coût ou la latence, pas la précision. Si tu construis un service backend sans contrainte de latence et avec du budget, ton gagnant pourrait être complètement différent du mien.
La profondeur de test doit suivre la viabilité. J'ai lancé 100+ benchmarks sur les modèles Gemini et ~5 sur les autres providers, de façon déséquilibrée. Volontairement. Ça a l'air injuste. Mais dès qu'un modèle tape dans un mur rédhibitoire, dépenser du budget de benchmark dessus c'est du gâchis. J'ai investi là où ça comptait.
Même prompt ne veut pas dire mêmes résultats. Les cinq fournisseurs ont reçu le même prompt système et les mêmes définitions d'outils. L'écart de précision : 26.5% à 74.5%. Le prompt a été conçu pour Gemini (c'est là que j'ai itéré), ce qui donne probablement un avantage à Gemini. Un prompt optimisé pour Haiku ou GPT pourrait réduire l'écart. Mais les contraintes de coût/latence les élimineraient quand même pour mon cas.
L'architecture unifiée a rentabilisé l'investissement. Construire l'agent pour 5 fournisseurs avec la même interface, c'était du boulot. Mais chaque comparaison était du pommes-pommes. Même prompt, mêmes outils, même scoring, même dataset. Pas de "oui mais peut-être que la version OpenAI a des outils différents". Si un modèle sous-performait, c'était le modèle (ou l'intégration API), pas le setup.
Les limites de ce benchmark
Je tiens à être clair sur ce que ce benchmark montre et ce qu'il ne montre pas.
Il montre comment ces modèles performent sur ma tâche spécifique (recherche de pays de fabrication via le web), avec mon prompt (optimisé pour Gemini), à mon échelle (app grand public, coûts serrés). Une tâche différente, un prompt différent, ou d'autres contraintes pourraient donner un classement complètement différent.
Le résultat de GPT-5.1 en particulier ne reflète peut-être pas la capacité du modèle. Si j'avais passé plus de temps sur l'intégration OpenAI, les résultats auraient pu s'améliorer. J'ai fait un choix pragmatique : les autres providers marchaient direct, j'ai investi mon temps là-dessus.
Et la profondeur de test est inégale. 3 runs sur Haiku contre 20+ sur Gemini 3 Flash, ça veut dire que j'ai beaucoup plus confiance dans les chiffres Gemini. Le résultat Haiku (67.6%) est peut-être un run malchanceux. Ou chanceux. Avec 1 run, impossible de savoir.
Ce que je sais : Gemini 3 Flash à 0.004$/trace et 13.5s me donne 74.5% de précision. C'est la combinaison sur laquelle je peux construire un produit. Pour l'instant.
Parce que ce benchmark est une photo, pas un verdict. Les prix baissent. Les modèles s'améliorent. La latence s'optimise. Haiku a été éliminé sur le coût, mais Anthropic change ses tarifs régulièrement. Grok a été éliminé sur la latence, mais xAI optimise activement la vitesse d'inférence. GPT-5.1 a peut-être juste besoin d'une intégration différente.
Les résultats sont factuels, mais pas définitifs. L'infra de benchmark reste. Quand le contexte change, je relance.
Prochain article : LLM-as-Judge, utiliser Claude pour auditer un agent Gemini. Comment j'ai automatisé le QA en faisant relire chaque trace par un modèle plus costaud, et les patterns qu'il a trouvés que j'aurais jamais vus à l'oeil.
Cet article fait partie d'une série sur la construction d'un agent IA en production pour Mio. Précédent : Pourquoi un agent IA a besoin d'un benchmark avant d'avoir besoin d'un prompt.
Questions fréquentes
-
Ça dépend de tes contraintes. Dans mes tests, Gemini 3 Flash tapait 74.5% de précision à 0.004$/trace et 13.5s de latence. Claude Haiku 4.5 faisait 67.6% mais à 0.019$/trace. GPT-5.1 : 26.5%. Les benchmarks publics ne prédisent pas la performance agentique. Il faut tester sur ta tâche.
-
GPT-5.1 renvoyait null ou confiance basse sur 20 items sur 34. C'est peut-être en partie un problème d'intégration (Responses API vs function calling natif), pas que le modèle. Mais à 26.5% sur le seul run, j'ai préféré investir mon temps sur les providers qui marchaient directement.
-
Dans mes tests : Gemini 3 Flash à 0.004$/trace, Flash Lite à 0.006$, Claude Haiku à 0.019$, GPT-4.1 à 0.014$, Mistral à 0.0006$, Grok 4 Fast à 0.001$. Pour une app grand public avec des milliers d'utilisateurs quotidiens, ces écarts font la différence entre viable et pas viable.
-
Pas linéairement. Gemini 2.5 Flash avait 45.6% de précision mais la pire fausse confiance (10.5 en moyenne). Flash Lite avait une précision plus basse (54-60%) mais beaucoup moins de fausse confiance (~5). Les modèles plus malins répondent à plus de questions, donc plus d'occasions de se tromper avec assurance.