Pourquoi trouver l'origine d'un produit est un problème d'IA
Un code-barres indique où une marque est enregistrée. Pas où le produit est fabriqué. Le préfixe GS1 correspond au pays de fabrication réel environ 40% du temps. Trouver la vraie réponse demande un raisonnement multi-étapes à travers des sources dispersées, incohérentes, et parfois trompeuses.
Prenez n'importe quel produit au supermarché. Retournez-le. Vous voyez le code-barres ? Les trois premiers chiffres indiquent dans quel pays la marque est enregistrée. Ça commence par 300-379 ? France. 400-440 ? Allemagne. 890 ? Inde.
La plupart des gens (moi y compris, avant de travailler là-dessus) pensent que c'est le pays de fabrication.
Ce n'est pas le cas. Pas du tout.
Une marque française peut enregistrer ses codes-barres en France et tout fabriquer en Chine. Une entreprise allemande peut produire en Pologne. Ce préfixe GS1 à 3 chiffres correspond au pays de fabrication réel environ 40% du temps. Autant jouer à pile ou face.

Je développe Mio, une application qui permet de scanner un code-barres et de trouver où un produit est fabriqué. Ce qui devait être un petit projet de base de données est devenu l'un des problèmes d'IA les plus intéressants que j'aie rencontrés.
Petit avertissement : je suis développeur, pas data scientist. Des trucs que je raconte dans cette série (la variance existe ! il faut plus de 3 cas de test !) feront sourire les ingénieurs ML. Mais la plupart des devs qui construisent avec des LLMs aujourd'hui n'ont pas de bagage en stats, et je parie qu'ils se heurtent aux mêmes murs que moi. Si mes essais-erreurs font gagner ne serait-ce que quelques heures à quelqu'un, ça me va.
Les données existent. Bonne chance pour les trouver.
Le truc frustrant, c'est que l'info existe. L'origine de fabrication de la plupart des produits est disponible quelque part. Enfouie dans une page produit d'un distributeur, stockée dans une base de données ouverte, imprimée sur l'emballage en police 6pt, ou sous-entendue par un label qualité qui impose légalement une région spécifique.
Sauf que justement ce "quelque part", c'est là tout le sel du problème !
L'information est fragmentée. Une base de données a le nom du produit mais pas l'origine. Un distributeur affiche "Pays de fabrication : Allemagne" dans l'onglet caractéristiques que personne ne consulte. Une base alimentaire ouverte fournit un code sanitaire qui suggère un lieu d'emballage, pas forcément le lieu de fabrication.
Elle est incohérente. "Made in France." "Fabriqué en France." "Pays de fabrication : FR." "Lieu de production : Normandie." La même information, une douzaine de formats selon les langues et les conventions.
Et surtout, elle est parfois trompeuse. Un distributeur peut afficher "Fabriqué en France" comme bannière promotionnelle sur tout son site, sans que ça concerne le produit que vous regardez. Amazon peut montrer "Pays d'origine : Chine" pour le compte du vendeur, pas pour le produit. Le site d'une marque proclame fièrement "Française depuis 1921" tout en fabriquant en Italie via une maison mère dont personne n'a entendu parler.

Ce n'est pas un problème qu'une base de données peut résoudre. C'est un problème de raisonnement.
Les approches évidentes. On les a toutes essayées.
"Il suffit de construire une base de données." C'est fait. On a intégré une base produit couvrant 69 millions d'articles. Elle contient noms, marques, catégories, labels, et pour certains produits, l'origine de fabrication. Quand ce champ est renseigné, c'est très fiable. Problème : il est renseigné pour peut-être 15-20% des produits. Les 80% restants donnent un nom et une marque, mais pas d'origine.
"Pourquoi ne pas scraper les sites des distributeurs ?" Essayé aussi. Certains distributeurs listent bien l'origine de fabrication dans les caractéristiques produit. Mais pas tous les produits, pas tous les distributeurs, et la structure HTML varie énormément. Un pipeline de scraping statique casse à chaque refonte de page produit. Ce qui arrive constamment. Et surtout : pour couvrir tous les codes-barres existants (et pas seulement les 69 millions qu'on a en base), il faudrait scraper l'intégralité des catalogues de dizaines de distributeurs, en continu. Rien qu'en coût et en maintenance, c'est intenable. L'approche agent règle ce problème : la recherche se fait à la demande, quand un utilisateur scanne un produit, et le résultat est mis en cache pour tous les suivants. Pas besoin de tout scraper à l'avance.
"Ce n'est pas réglementé ?" Dans l'UE, le pays de fabrication n'est pas obligatoire sur la plupart des étiquettes. L'alimentaire est mieux couvert, mais même l'alimentaire a des exceptions. Et les bases réglementaires, quand elles existent, sont rarement exploitables par une machine.
Chaque approche seule plafonne à ~20-30% de couverture. Et aucune ne peut vous dire à quel point être confiant dans le résultat. Un "Made in Germany" explicite sur le site du fabricant n'a rien à voir avec une supposition du type "probablement Allemagne, vu que la marque est allemande et que le code-barres commence par 400."
Pourquoi c'est en réalité un problème de raisonnement
Le déclic est venu quand on a arrêté de chercher une meilleure base de données et qu'on a compris le vrai problème : trouver où un produit est fabriqué, c'est une tâche de raisonnement multi-étapes avec des preuves incertaines.
Un exemple réel tiré de notre benchmark : une brosse à dents avec un code-barres français, vendue par une marque fondée en France en 1921, aujourd'hui détenue par un conglomérat italien. La première recherche web renvoie une page distributeur qui affiche "Fabriqué en France". Mais est-ce que ça concerne ce produit, ou c'est une bannière promo pour la gamme "produits français" du distributeur ? Un second résultat montre que la maison mère exploite des usines en Italie, Pologne et France. Une base ouverte n'a pas de données de fabrication mais liste un code sanitaire commençant par "IT", ce qui suggère un emballage italien.
Pour démêler tout ça, il faut :
- Chercher sur plusieurs sources, dans plusieurs langues
- Lire les pages en entier, pas juste les extraits de recherche, pour vérifier que "Made in X" concerne bien ce produit spécifique
- Croiser les sources : le code sanitaire correspond-il aux sources web ? La structure du groupe explique-t-elle la contradiction ?
- Calibrer la confiance. C'est vérifié ou c'est une hypothèse ?
- Savoir quand s'arrêter. Certains produits ne sont pas traçables depuis les sources publiques. "Inconnu" vaut mieux qu'une mauvaise réponse.
C'est exactement le territoire des agents IA. Pas un simple appel à un LLM. Pas du RAG. Un agent qui décide quoi faire ensuite en fonction de ce qu'il a trouvé jusque-là.
En pratique, voilà ce que ça donne : vous scannez un produit en magasin, et en quelques secondes vous obtenez le pays de fabrication, un niveau de confiance, le raisonnement de l'agent, et les liens vers les sources.
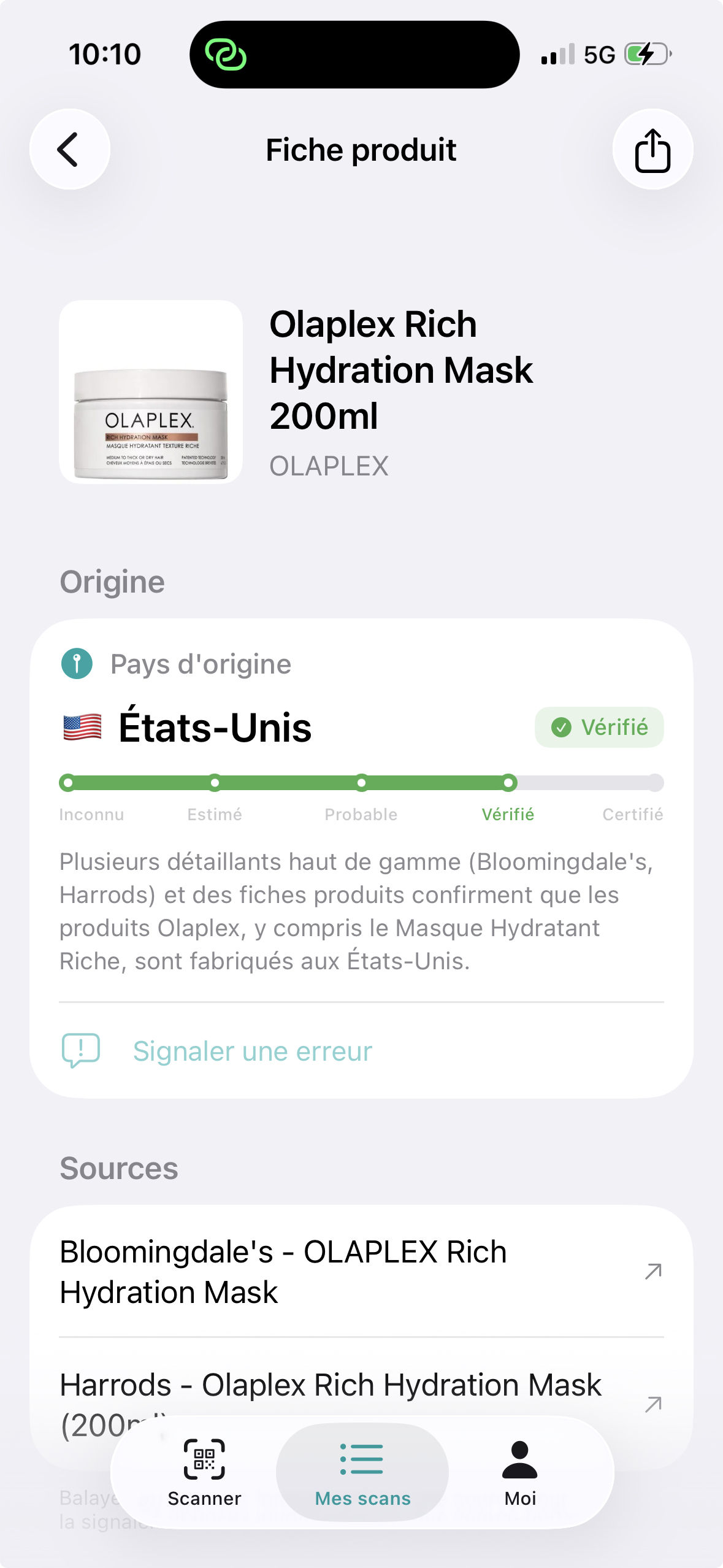
L'architecture (vue d'ensemble)
Le système suit une chaîne de priorité simple :
- Base de données d'abord : quand une base structurée a l'origine avec une confiance élevée, on la renvoie instantanément. Pas besoin de LLM. Ça couvre ~15-20% des requêtes en quelques millisecondes.
- Agent pour le reste : un agent LLM avec accès à la recherche web et à la lecture de pages, chargé de trouver et vérifier le pays de fabrication. Il cherche, lit des pages, croise les sources, et soumet une réponse avec un niveau de confiance.
- La confiance comme donnée de sortie à part entière : chaque résultat est accompagné d'un niveau "vérifié" (source explicite), "probable" (preuves indirectes), ou "faible" (pas trouvé grand-chose). Cette distinction compte plus que le pays lui-même pour la confiance des utilisateurs.
L'agent peut décider dynamiquement : chercher avec d'autres mots-clés, lire une page prometteuse, essayer une autre langue, ou abandonner et signaler une confiance faible. Cette boucle adaptative est tout l'intérêt.

Contrainte importante : ça tourne en temps réel. Un utilisateur scanne un produit en magasin et s'attend à une réponse en quelques secondes, pas en minutes. Et chaque recherche web, chaque lecture de page coûte de l'argent. Le système doit être précis, rapide, et peu coûteux. Un modèle qui donne 5% de bonnes réponses en plus mais coûte 5 fois plus par scan et prend 30 secondes au lieu de 10 n'est pas viable pour une app grand public. Trouver le bon équilibre entre précision, coût et latence s'est avéré aussi difficile que le problème de précision lui-même.
Cinq pièges qui plombent la précision
On s'est pris des murs que personne ne mentionne dans les tutos. Quelques uns de ceux qui nous ont coûté le plus de temps :
1. Le piège du préfixe GS1
L'agent voit un code-barres commençant par 300 (France) et s'ancre inconsciemment sur la France, même quand les preuves pointent ailleurs. On a dû explicitement casser ça : "Le préfixe du code-barres indique où la marque est enregistrée. Ce N'EST PAS une preuve de l'origine de fabrication." Sans ça, l'agent a un fort biais vers la France. 5 des 7 cas de fausse confiance dans notre premier benchmark étaient l'agent qui disait "France" à tort.
2. Le piège marque ≠ usine
Moulinex est une marque française. Elle fabrique en Chine, Pologne et France selon la gamme. Notre agent a dit avec confiance "Fabriqué en France" pour des produits fabriqués sur un autre continent, parce que la page Wikipédia de la marque dit "entreprise française." "Marque française" ne veut pas dire "produit français." Évident avec le recul. Pas évident pour un LLM.
3. Le piège du badge distributeur
C'était notre source numéro un de fausse confiance. Certains sites de distributeurs affichent des badges liés à l'origine ("Fabriqué en France", "Produit local") comme éléments promotionnels sur l'ensemble de leur site. Ces badges apparaissent dans les extraits de recherche juste à côté du listing produit. L'agent ne peut pas distinguer une mention spécifique au produit d'une bannière marketing sans lire la page complète.
On a eu des cas où l'agent déclarait "vérifié : Fabriqué en France" sur la base d'un badge qui concernait une gamme de produits complètement différente. Brutal.
4. Le piège "UE"
Beaucoup de produits indiquent "Fabriqué en UE." Techniquement correct, pratiquement inutile. 27 États membres. On a passé une semaine à essayer de gérer ça au niveau du modèle. Le modèle a complètement ignoré nos instructions, quelle que soit la version du prompt. Parfois la bonne réponse, c'est d'accepter la limitation.
5. Emballage ≠ fabrication
Les codes sanitaires (codes EMB) indiquent où un produit a été emballé, pas où il a été fabriqué. Un produit fabriqué en Espagne peut être emballé en France et porter un code français. Les données semblent fiables, c'est exactement ce qui les rend dangereuses.
Ce qui compte vraiment (après 108 benchmarks)
On a lancé 108 benchmarks en trois semaines. Sept modèles de quatre fournisseurs. Six versions majeures du prompt avec des dizaines de sous-variantes. Un jeu de test de référence, curé à la main, passé de 21 à 57 produits en ajoutant progressivement des cas plus difficiles. Chaque exécution a été comparée à des données de référence vérifiées, avec la version du prompt et le SHA git enregistrés sur chaque trace dans Langfuse pour une reproductibilité totale.
On est passé de 42% de précision à 78%. En vrac, les leçons :
La fausse confiance est la métrique qui compte. Pas la précision brute. Un système qui dit "je ne sais pas" quand il ne sait pas est infiniment plus fiable qu'un système qui répond à tout mais se trompe 15% du temps. On appelle ça "fausse confiance" : l'agent dit "vérifié" et il a tort. C'est le chiffre qu'on optimise en priorité.
Le fossé entre les types de sources est énorme. Un champ structuré en base de données, c'est de l'or. Une mention explicite "Made in X" sur le site du fabricant, c'est de l'argent. Un listing distributeur avec l'origine dans les caractéristiques, c'est du bronze. Un extrait de recherche mentionnant un pays près d'un nom de produit, c'est du plomb : lourd et potentiellement toxique. On l'a appris à nos dépens.
L'optimisation est tridimensionnelle. On a itéré sur les prompts, l'outillage et les modèles, et ce sont les interactions entre les trois qui comptent. Des règles de prompt qui échouaient sur un petit modèle fonctionnaient parfaitement sur un modèle plus intelligent. L'exécution parallèle des outils n'a aidé que parce que le modèle était assez malin pour regrouper les appels et que le prompt lui disait de le faire. On a doublé les résultats de recherche de 5 à 10 par requête et la précision a chuté, non pas parce que "plus c'est mal" mais parce que ce modèle ne pouvait pas gérer le bruit. Les meilleurs résultats sont venus en trouvant la bonne combinaison sur les trois axes.
L'honnêteté intellectuelle n'est pas négociable. On n'audite pas des usines. On ne certifie pas des chaînes logistiques. On agrège des informations publiquement disponibles, on attribue un niveau de confiance, et on les présente de manière transparente. Si une marque ment sur son site, on relayera ce mensonge, et le système de confiance reflétera combien de sources indépendantes l'ont confirmé. Être clair sur ce que le système peut et ne peut pas faire est à la fois le choix éthique et celui qui inspire le plus de confiance.
Ce pattern est partout
Si j'écris tout ça, c'est parce que cette structure de problème est bien plus courante qu'on ne le pense :
- La réponse existe quelque part dans les sources publiques
- Aucune source n'est fiable à elle seule
- Le chemin de raisonnement dépend de ce qu'on trouve à chaque étape
- La calibration de la confiance est aussi importante que la réponse elle-même
- Le problème semble trivial jusqu'à ce qu'on essaie de l'automatiser
Ce sont les problèmes où les agents IA prouvent vraiment leur valeur. Pas parce qu'une étape individuelle est difficile (chercher, lire une page web, comparer deux chaînes de caractères) mais parce qu'orchestrer ces étapes demande du jugement. Quand chercher à nouveau, quand lire la page complète, quand accepter les preuves, quand abandonner.
108 benchmarks, 7 modèles, 6 versions de prompt, 3 semaines. Le parcours de "ça marche à peu près" à "c'est assez fiable pour la prod" a été bien plus intéressant, et bien plus contre-intuitif, que ce que j'imaginais. Des règles de prompt qui échouaient sur un modèle fonctionnaient sur un autre. Des changements que j'avais considérés comme des échecs sont devenus des succès dans un contexte différent. Les plus gros gains sont venus d'endroits auxquels je ne m'attendais pas.
La suite au prochain épisode.
Prochain article : Le prompt engineering qui n'a pas marché (et ce qui a marché). Et pourquoi "ça a l'air mieux sur quelques exemples" est la phrase la plus dangereuse en ingénierie IA.
Je développe Mio, une app qui recherche l'origine de fabrication des produits à partir de leur code-barres. 108 benchmarks, 7 modèles, un jeu de test de référence curé à la main, et un système LLM-as-judge qui vérifie le travail de l'agent. Si vous avez construit des pipelines d'évaluation pour des agents IA ou travaillé sur des problèmes similaires, j'aimerais beaucoup échanger.
Questions fréquentes
-
Non. Les 3 premiers chiffres d'un code-barres (préfixe GS1) indiquent où la marque est enregistrée, pas où le produit est fabriqué. Un préfixe GS1 français (300-379) ne correspond au pays de fabrication réel qu'environ 40% du temps.
-
La fausse confiance, c'est quand un agent IA rapporte un résultat avec une haute confiance, mais que le résultat est faux. Par exemple, déclarer "vérifié : Fabriqué en France" alors que le produit est en réalité fabriqué en Chine. C'est le mode d'échec le plus dangereux car il détruit la confiance des utilisateurs.
-
Les bases de données ne couvrent que 15-20% des produits pour l'origine de fabrication. Le reste nécessite un raisonnement multi-étapes : chercher sur le web, lire des pages de distributeurs, croiser les sources, et évaluer la qualité des preuves. C'est fondamentalement une tâche de raisonnement, pas de récupération de données.
-
Après 108 benchmarks et de nombreuses itérations, l'agent atteint environ 78% de précision sur un jeu de test curé avec des produits de difficulté variable. Chaque résultat inclut un niveau de confiance (vérifié, probable, ou faible) pour que les utilisateurs sachent à quel point se fier au résultat.